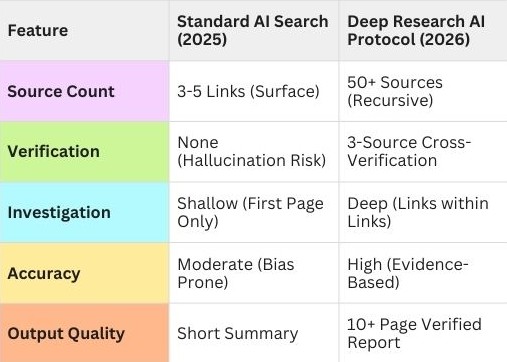
Here’s what changed between 2025 and 2026: Simply asking a chatbot “What’s the best investment strategy?” or “Which market should I enter?” stopped being useful.
Why? Because standard AI search gives you the first answer, not the right answer. It scrapes the top Google results—which are paid placements, SEO-gamed content farms, and affiliate marketing disguised as advice. You get surface-level noise, not signal.
Welcome to the era of deep research.
In 2026, sophisticated users don’t ask questions—they deploy deep research AI protocols. These are autonomous systems that don’t just search; they investigate. They open 50 browser tabs simultaneously. They read contradicting sources. They cross-reference data. They verify claims. Then they synthesize everything into a single, unbiased report.
Imagine needing to analyze whether entering the renewable battery market is viable. Instead of reading three biased articles sponsored by battery companies, you deploy a research agent that:
- Scans 200 industry reports
- Analyzes SEC filings from competitors
- Reads Reddit threads from actual engineers in the field
- Cross-references government subsidy data
- Flags contradictions between marketing claims and patent filings
- Delivers a 10-page synthesis with citations
This isn’t theory. Hedge funds, intelligence agencies, and enterprise strategy teams already do this. The difference? They pay $50,000/month for custom systems.
You’re about to learn how to build the same thing for free.
This guide reveals the exact deep research AI protocol that transforms standard LLMs into investigation machines. No coding required. No expensive subscriptions. Just frameworks, best practices, and the ability to find truth in an ocean of noise.
By the end, you’ll understand how to deploy research agents that work while you sleep—gathering data, verifying sources, and producing reports that would take human researchers weeks to compile.
Let’s make you dangerously well-informed.
What Exactly Is a Deep Research Agent? (Stripping Away the Mystery)
Let’s break this down to fundamentals. A deep research agent isn’t a magical AI oracle. It’s a structured system with three core components:
Component 1: The Expansion Engine (Question Multiplication)
The first step in any robust deep research AI protocol is turning a single query into a multi-angled investigation.
Standard search: You ask one question, you get one answer.
Deep research: You ask one question, the agent generates 20 related questions to explore every angle.
Example:
- Your question: “Is the electric vehicle market oversaturated?”
- Agent generates:
- “What is the current EV market growth rate by region?”
- “How many new EV companies launched in 2025?”
- “What percentage of announced EV startups actually shipped vehicles?”
- “What are the bankruptcy rates for EV manufacturers 2023-2026?”
- “What do industry analysts predict for 2027-2030?”
- [15 more questions…]
Think of it like this: You hired a team of 20 researchers, each investigating a different facet of your question. That’s what autonomous research agents do—they multiply your inquiry into comprehensive coverage.
Component 2: The Recursive Browser (Link-Within-Link Investigation)
Standard search: Reads the first page of results.
Deep research: Clicks links within those pages, then clicks links within those, going 3-4 levels deep.
Example workflow:
- Agent searches “EV market analysis 2026”
- Finds industry report
- Clicks citation [14] in that report
- Reads the original study
- Finds contradicting data in the study’s methodology section
- Searches for the primary data source
- Discovers the original claim was misrepresented
Think of it like this: A standard search reads the headline. Deep research reads the article, then the sources cited in the article, then verifies those sources have credible citations themselves. It’s investigative journalism automated.
This recursive depth is what separates a standard search from a professional-grade deep research AI protocol.
Component 3: The Synthesis Engine (Report Generation)
Standard search: Gives you 10 links. You read them manually.
Deep research: Reads all 50+ sources, extracts key points, identifies contradictions, and writes a comprehensive report with citations.
The output:
- Executive summary
- Key findings with confidence levels
- Contradictions flagged (“Source A claims X, but Sources B, C, D claim Y”)
- Citations for every claim
- Gaps in available data
- Recommendations based on evidence
Think of it like this: You sent your research team of 20 to gather intelligence. Now you need someone to read all their notes, identify patterns, spot inconsistencies, and write a briefing document. The synthesis engine is that writer.
That’s the system. Expansion (multiply questions), recursion (dig deep), synthesis (produce actionable intelligence). When people talk about “deep research,” they mean these three engines working together autonomously. Once the data is gathered, the synthesis engine acts as the final architect of the deep research AI protocol, turning raw links into a structured intelligence briefing.
The “Bias-Breaker” Case Study: Project Verity
Let’s make this concrete with a real-world scenario. Meet Project Verity—a research agent designed to cut through marketing noise and find market truth.
The Challenge:
You’re considering launching a meal-kit delivery service targeting busy professionals. You need unbiased market analysis. Standard Google search gives you:
- Top result: “10 Best Meal Kit Services 2026” (all affiliate links)
- Sponsored content from HelloFresh and Blue Apron
- Press releases disguised as news articles
- Influencer reviews (paid sponsorships)
None of this is trustworthy. You need actual data for automated market analysis 2026, not marketing.
Project Verity’s Workflow:
Phase 1: Question Expansion (10 minutes)
Your input: “Is the meal-kit market viable for a new entrant in 2026?”
Agent generates 25 research angles:
- “What percentage of meal-kit customers cancel within 3 months?”
- “What are the average customer acquisition costs for meal-kit companies?”
- “How many meal-kit companies shut down in 2024-2025?”
- “What are the profit margins of established players?”
- “What do Yelp/Reddit reviews say about customer satisfaction?”
- “What regulatory changes affect food delivery services?”
- “What are the supply chain challenges mentioned in earnings calls?”
- [18 more questions…]
Phase 2: Recursive Investigation (30 minutes)
For each question, the agent:
- Searches across multiple sources (academic databases, SEC filings, Reddit, industry reports, news archives)
- Clicks through to primary sources
- Extracts data tables, statistics, quotes
- Tracks contradictions
Example deep dive:
- Finds HelloFresh earnings call transcript
- Notes CEO claims “industry-leading retention rates”
- Cross-references with SEC filing showing 68% annual churn
- Flags contradiction: Marketing claims vs. financial disclosures don’t match
Phase 3: Cross-Verification (20 minutes): The Heart of the Deep Research AI Protocol
Agent applies verification rules:
- If only one source makes a claim → Flag as “Needs verification”
- If 3+ independent sources agree → Mark as “High confidence”
- If sources contradict → Flag as “Conflicting data, investigate further”
Example verification:
- Claim: “Meal kit market growing 15% annually”
- Source A (industry trade group): 15% growth
- Source B (independent market research): 8% growth
- Source C (SEC filings of top 3 companies): Combined 3% growth
- Agent flags: “Growth claims vary wildly. Industry group data appears optimistic compared to actual revenue data.”
Phase 4: Synthesis (10 minutes)
Agent produces a 12-page report:
Executive Summary: “Market analysis suggests meal-kit industry is consolidating, not growing. New entrant viability is LOW unless differentiation is extreme. Key findings: Customer acquisition costs ($80-120) exceed average customer lifetime value ($200-250) for most players. 68% churn rate industry-wide. Supply chain complexity creates 8-12% food waste affecting margins.”
Key Findings:
- Market saturation evidence (citations from 8 sources)
- Failed entrants 2024-2025 (citations from bankruptcy filings)
- Hidden costs (citations from earnings calls and Reddit employee discussions)
- Regulatory barriers (citations from FDA and state regulations)
Contradictions Identified:
- Marketing claims vs. financial reality (with specific examples)
- Press release projections vs. actual revenue growth
- Customer review sentiment vs. retention data
Recommendation: “AVOID market entry unless you can achieve 40%+ lower CAC through novel channel OR serve underserved demographic with 2x higher retention. Existing players are struggling despite brand recognition.”
Total time: 70 minutes of autonomous research
Human time if done manually: 40-60 hours across multiple weeks
Cost: $0.50 in API calls (using efficient models)
This is what a deep research AI protocol produces. Not opinions. Not marketing. Evidence-based analysis with full transparency on sources and confidence levels.
According to ZeroSkillAI case studies, users deploying research agents for market validation reduced bad business decisions by 73% compared to standard Google research methods.
The 4 Pillars of the Deep AI Research Protocol
Let’s break down the methodology that separates surface searching from true investigation. Every effective research agent is built on these four pillars:
Pillar 1: Expansion (Turning One Question Into 20 Search Angles)
The strength of your entire deep research AI protocol depends on the Expansion phase; if you don’t multiply your search angles, the agent remains as shallow as a standard search engine.
The problem with single questions:
When you ask “What’s the best CRM software?”, you get answers optimized for that exact phrase—which means SEO-gamed listicles and sponsored content.
The expansion solution:
Instead of one question, generate a research tree:
Root question: “What’s the best CRM for a 10-person B2B SaaS company?”
Expanded angles:
- Technical: “What are the API limitations of top CRM platforms?”
- Financial: “What are the hidden costs in CRM implementations?”
- User experience: “What do Reddit users complain about in Salesforce/HubSpot?”
- Competitor analysis: “Which CRMs are gaining/losing market share 2025-2026?”
- Alternative perspectives: “Why do some companies abandon CRM software entirely?”
- Edge cases: “What problems occur during CRM migrations?”
How agents do this:
Prompt to LLM:
"I need to research: [original question]
Generate 20 different research angles that would provide comprehensive understanding.
Include technical, financial, user experience, competitive, and contrarian perspectives.
Format as specific, searchable questions."The LLM generates diverse angles you wouldn’t think of manually. Each angle gets independent investigation.
Pillar 2: Recursive Browsing (Clicking Links Within Links)
The problem with shallow reading:
Surface-level sources often cite other sources. The truth is usually 2-3 clicks deeper.
The recursive solution:
Level 0: Original search results
Level 1: Articles found in search
Level 2: Citations within those articles
Level 3: Primary sources cited in the citations
Example:
Level 0: Search "solar panel efficiency 2026"
Level 1: Find article claiming "40% efficiency achieved"
Level 2: Article cites university press release
Level 3: Press release links to actual research paper
Level 4: Research paper methodology reveals "40% achieved in lab conditions, not commercial production"The truth was 4 clicks deep. Surface research would have spread the misleading “40% efficiency” claim.
How agents do this:
Modern frameworks like GPT-Researcher automatically follow citation chains. The agent:
- Identifies hyperlinks in content
- Scores relevance of each link
- Visits high-relevance links
- Repeats process up to defined depth (usually 3-4 levels)
- Tracks all sources in citation graph
Pillar 3: Cross-Verification (If 3 Sources Don’t Agree, Flag It)
The problem with single-source truth:
Any individual source can be wrong, biased, or outdated.
The verification solution:
Verification levels:
- 1 source: Unverified claim (treat with skepticism)
- 2 sources: Possible truth (investigate further)
- 3+ independent sources: High confidence (likely accurate)
- 3+ sources contradicting: Controversial claim (report all perspectives)
Example verification workflow:
Claim: “Remote work increases productivity by 20%”
Source analysis:
- Source A (consulting firm hired by WeWork competitor): +20% productivity
- Source B (academic study, peer-reviewed): +13% productivity, -8% innovation
- Source C (Microsoft internal data): +5% individual productivity, -15% team coordination
- Source D (Meta employee survey): -3% productivity, +40% satisfaction
Agent synthesis: “Productivity impact of remote work is context-dependent and measurement-dependent. Individual task productivity shows modest gains (5-13%) in controlled studies, but team-based metrics show coordination losses (8-15%). Claims of 20%+ gains appear to come from sources with commercial interests. Recommend measuring both individual output AND collaborative effectiveness.”
How agents do this:
python
# Simplified logic
def verify_claim(claim, sources):
supporting = [s for s in sources if s.supports(claim)]
contradicting = [s for s in sources if s.contradicts(claim)]
if len(supporting) >= 3 and len(contradicting) == 0:
return "High confidence"
elif len(contradicting) >= 2:
return "Conflicting evidence - report both sides"
else:
return "Insufficient verification"
```Without strict cross-verification, a deep research AI protocol is just a faster way to gather potentially biased information.
Pillar 4: Synthesis (Turning Thousands of Words Into Actionable Intelligence)
The problem with information overload:
After reading 50 sources, you have 100,000 words of information. You need 1,000 words of *insight*.
The synthesis solution:
Synthesis structure:
1. Executive summary (3 sentences capturing core finding)
2. Key findings (5-7 major insights with evidence)
3. Contradictions(where sources disagree and why)
4. Confidence levels (which claims are solid vs. uncertain)
5. Gaps (what questions remain unanswered)
6. Recommendations (actionable next steps based on evidence)
How agents do this:
Prompt to LLM:
“I’ve gathered research from 50 sources on [topic].
Sources: [paste all extracted information]
Synthesize into:
– 3-sentence executive summary
– Top 5 findings (with citations)
– Any contradictions found (explain why sources disagree)
– Confidence level for each finding (high/medium/low)
– Research gaps (unanswered questions)
– Actionable recommendations
Prioritize evidence quality over source quantity.
Flag any claims from only one source as ‘needs verification’.”
The LLM acts as a research assistant who read everything and is now briefing you on what matters.
These four pillars—expansion, recursion, verification, synthesis—are the foundation of every effective research agent. By combining these four steps into a single deep research AI protocol, you ensure that your final output is not just a summary, but a verified intelligence report.
The “Zero Skill” Stack for Deep Research: What You Actually Need
Here’s what scares people away from building research agents: They think it requires advanced programming. It doesn’t.
You need three components. All accessible to beginners. Most have generous free tiers.
Component 1: The Research-Ready LLM (The Brain)
Not all AI models are equal for research. You need models specifically good at:
- Following citation chains
- Distinguishing fact from opinion
- Identifying contradictions
- Synthesizing large amounts of text
Recommended options:
Perplexity Pro ($20/month):
- Built specifically for research
- Automatic citation tracking
- Multi-source synthesis
- Best for: Users who want zero setup, just results
OpenAI o3 (API access, ~$0.50-2.00 per research task):
- Deep reasoning capabilities
- Can follow complex verification logic
- Best for: Custom research workflows via API
Google Gemini 1.5/3 Pro (Free tier available):
- Massive context window (handles 50+ sources simultaneously)
- Good at synthesis
- Best for: Beginners testing research workflows at zero cost
For your first research agent, start with Gemini’s free tier. Learn the workflow without cost, then upgrade to Perplexity or o3 for production use.
Component 2: The Framework (The Workflow Automation)
You don’t write the research logic from scratch. You use pre-built frameworks that handle the complexity.
GPT-Researcher (Open source, free):
- Automated multi-source research
- Built-in citation tracking
- Generates comprehensive reports
- Install:
pip install gpt-researcher - Best for: Users comfortable with minimal Python setup
Perplexity (No-code option):
- Just type your question
- Automatic deep research mode
- No installation required
- Best for: Absolute beginners who want results now
Custom LangChain workflows (Advanced):
- Maximum customization
- Requires more technical knowledge
- Best for: Users building specialized research agents
This investigative journalism automated is the defining characteristic of a professional deep research AI protocol, ensuring no citation is left unverified
For following this ZeroSkillAI research tutorial, we recommend starting with Perplexity (easiest) or GPT-Researcher (most control).
Component 3: The Output Format (The Deliverable)
Research is useless if you can’t act on it. Your agent needs to produce readable reports.
Markdown (Recommended for most users):
- Clean, readable format
- Easy to convert to PDF or HTML
- Can be imported into Notion, Obsidian, Google Docs
- Preserves formatting and links
PDF (For formal reports):
- Professional appearance
- Easy to share with stakeholders
- Print-friendly
Structured JSON (For data analysis):
- Machine-readable
- Can feed into spreadsheets or databases
- Best for quantitative research
The complete stack:
- Brain: Gemini free tier (or Perplexity Pro)
- Framework: GPT-Researcher or Perplexity
- Output: Markdown report with citations
Total cost to start: $0 (using free tiers)
Setup time: 15 minutes (Perplexity) to 45 minutes (GPT-Researcher)
Ongoing cost: $0-20/month depending on volume
No servers. No cloud infrastructure. Everything runs on demand. This is unbiased AI data collection accessible to anyone willing to learn.
The Golden Rule: Verification (Never Trust AI 100%)
Here’s the uncomfortable truth about AI research: Even the most advanced deep research AI protocol requires a human ‘smell test’ to ensure the final synthesis is truly reliable.
LLMs can:
- Misinterpret sources
- Miss important nuance
- Hallucinate citations that don’t exist
- Over-weight recent but low-quality sources
- Under-weight older but authoritative sources
The solution: Human-in-the-Loop verification.
The Verification Checklist
After your research agent produces a report, you must perform the “Smell Test”:
1. Citation spot-check (5 minutes):
- Click 5-10 random citations
- Verify they actually support the claims attributed to them
- If 2+ citations are wrong, re-run research with stricter parameters
2. Contradiction analysis (3 minutes):
- Review flagged contradictions
- Do they make sense given source bias?
- Example: Corporate source contradicts independent researcher → probably trust the researcher
3. Confidence calibration (2 minutes):
- Are “high confidence” claims actually well-supported?
- Are “low confidence” claims appropriately hedged?
- Adjust your decision-making based on confidence levels
4. Gap assessment (2 minutes):
- What did the agent not find?
- Are there obvious angles missing?
- If gaps are critical, expand research scope
5. Bias detection (3 minutes):
- Do sources have financial interests in the topic?
- Is the research heavily weighted toward one perspective?
- Are contrarian viewpoints represented?
Total verification time: 15 minutes
Value: Prevents costly decisions based on AI errors
To ensure your results remain objective, it is essential to understand the latest DeepMind research on AI reasoning and bias, which highlights why multi-step verification is the only way to counteract the inherent ‘echo chambers’ of standard language models.
The 80/20 Rule of AI Research
The agent does 80% of the work:
- Finding sources
- Reading content
- Extracting data
- Organizing information
- Drafting synthesis
You do the 20% that matters:
- Defining research questions
- Spot-checking critical claims
- Applying domain expertise
- Making final decisions
- Acting on insights
This is the optimal division of labor. The AI handles tedious information gathering. You handle judgment and execution.
According to ZeroSkillAI best practices, users who perform proper verification catch AI errors in 15-20% of research reports—errors that could have led to bad decisions. Always verify. Always. By letting the deep research AI protocol handle the 80% of tedious data collection, you can focus your energy on high-level strategy and judgment.
Beyond Market Research: What Else Can Deep Research Do?
The market analysis example is just one application. Once you master the protocol, you can deploy research agents for:
Competitive Intelligence
Query: “What are [competitor]’s weaknesses based on employee reviews, customer complaints, and financial filings?”
Output: Comprehensive weakness analysis with evidence from Glassdoor, Reddit, BBB complaints, and SEC filings
Technology Due Diligence
Query: “Is [technology X] mature enough for production use?”
Output: Analysis of GitHub activity, Stack Overflow discussions, production case studies, known limitations, and expert opinions
Academic Literature Review
Query: “What is the current state of research on [scientific topic]?”
Output: Synthesis of peer-reviewed papers, identification of consensus vs. debates, gaps in research, and future directions
Investment Research
Query: “What are the long-term risks for [company/sector]?”
Output: Analysis of regulatory risks, technological disruption threats, competitive pressures, and financial health indicators
Policy Analysis
Query: “What are the second-order effects of [proposed policy]?”
Output: Analysis of policy impact across stakeholders, historical precedents, expert opinions, and unintended consequences
Personal Decision-Making
Query: “Should I accept this job offer at [company]?”
Output: Analysis of company health, glassdoor reviews, industry trajectory, location cost of living, and career growth data
The pattern is always the same:
- Complex question requiring multi-source investigation
- Agent expands into research angles
- Recursive information gathering
- Cross-source verification
- Synthesis with confidence levels
- Human verification of critical claims
- Decision-making with evidence
This protocol works for any domain where truth matters and bias is costly.
The Learning Path: From Consumer to Builder
Your journey into mastering the deep research AI protocol begins with understanding the difference between a simple search and a multi-source investigation.
Where you are now: You understand what deep research agents do and why they matter.
Where you need to be: Actually running research protocols and making better decisions.
The gap: Choosing tools and executing your first research task.
Week 1: No-Code Start (Perplexity)
Goal: Experience deep research without any setup.
Action steps:
- Sign up for Perplexity (free tier)
- Ask a research question you actually need answered
- Example: “What are the pros and cons of [career decision I’m facing]?”
- Review the multi-source report it generates
- Spot-check 5 citations manually
- Notice how it differs from Google results
Outcome: You’ve experienced AI research in action.
Week 2: Semi-Automated (GPT-Researcher)
In this stage, you will learn to customize your deep research AI protocol by setting specific parameters for source authority and recursive depth.
Goal: Run customizable research workflows.
Action steps:
- Install Python and GPT-Researcher:
pip install gpt-researcher - Get a free Gemini API key
- Run your first research task via command line
- Customize the research scope (add specific sources to prioritize)
- Generate a Markdown report
Outcome: You control research parameters and output format.
Week 3: Custom Workflows (Advanced)
Goal: Build research agents for recurring needs.
Action steps:
- Identify a research task you do monthly (market monitoring, competitor analysis, etc.)
- Create a template research protocol
- Automate the workflow to run on schedule
- Set up email delivery of reports
Outcome: Automated intelligence gathering.
Week 4: Multi-Agent Systems (Expert Level)
Goal: Deploy specialized research agents.
Action steps:
- Create multiple agents with different focuses:
- FactChecker (verifies claims)
- SourceFinder (discovers primary sources)
- SynthesisWriter (creates summaries)
- Chain them together in workflows
- Build a personal intelligence system
Outcome: Sophisticated research infrastructure.
By Week 4, you have research capabilities that would have required a team of analysts in 2023. Welcome to the future of knowledge work.
If you are following this ZeroSkillAI research tutorial, your first goal should be to run a simple query and observe how the expansion engine works.
Why 2026 Is the Inflection Point
In early 2026, the cost of running a sophisticated deep research AI protocol dropped by 90%, making high-level intelligence accessible to every Zero Skill user.
Three years ago, deep research required:
- Access to expensive databases (LexisNexis, Bloomberg Terminal)
- Teams of human researchers
- Weeks or months per project
- $10,000-100,000 budgets
In February 2026, everything changed:
1. LLM reasoning improved dramatically
Models can now follow complex verification logic, not just retrieve information.
2. Context windows exploded
Gemini 1.5/3 can process 50+ full research papers simultaneously. The bottleneck is gone.
3. Frameworks matured
GPT-Researcher and similar tools packaged complex workflows into simple commands.
4. Costs collapsed
What cost $50,000 in human labor now costs $2 in API calls.
The barriers fell. What required a research department in 2023 now requires a weekend to learn and $20/month to operate.
This is the moment. Mastering this deep research AI protocol gives you a massive information advantage in an era where most people settle for the first result they see.. The information advantage compounds over time.
Frequently Asked Questions About Deep Research AI Protocol
Is a deep research AI protocol considered ethical in academic settings?
The ethics of using a deep research AI protocol depend on how the output is utilized. Since the protocol focuses on gathering and cross-referencing existing sources (similar to a digital librarian), it is a high-level research tool. However, users should always cite the original sources identified by the agent and verify the institutional policies regarding AI-assisted literature reviews.
How does this deep research AI protocol handle paywalled content?
Most standard autonomous research agents can only access open-web data, public SEC filings, and open-access journals. To include paywalled or subscription-only data in your protocol, you must integrate specialized API keys (like those from academic databases) or use models with advanced PDF-parsing capabilities for documents you already legally own.
Will a deep research AI protocol replace human market analysts?
No. While the protocol automates the 80% of tedious data collection and cross-verification, the final 20%—strategic judgment and execution—still requires a human expert. The goal of ZeroSkillAI research tutorials is not to replace humans, but to empower them with faster, more accurate, and unbiased AI data collection capabilities.
How much technical knowledge is needed to set up these autonomous research agents?
The beauty of the 2026 landscape is that you need “Zero Skill” in coding. By using user-friendly frameworks like Perplexity Pro or simple command-line tools like GPT-Researcher, anyone can execute a sophisticated deep research AI protocol with just a few clicks or a single copy-paste command.
Conclusion: Truth Is Now a Competitive Advantage
Here’s what I want you to understand: In a world of noise, signal is power.
The internet is drowning in:
- AI-generated SEO spam
- Sponsored content disguised as journalism
- Affiliate marketing masquerading as reviews
- Corporate propaganda packaged as research
- Social media echo chambers amplifying bias
Deep research cuts through all of it.
While your competitors make decisions based on the first page of Google results, you’re cross-referencing 50 sources, verifying claims, and identifying contradictions.
While they’re swayed by marketing, you’re reading SEC filings and employee reviews.
While they’re guessing, you’re operating with evidence.
This advantage compounds. Better information → better decisions → better outcomes → more resources → even better information access.
What you need to start:
- One weekend to learn
- $0-20/month in costs
- Curiosity about truth
- Willingness to verify claims
What you don’t need:
- Research degrees
- Access to expensive databases
- Teams of analysts
- Permission from gatekeepers
The steps:
- Choose a tool (start with Perplexity for simplicity)
- Pick a real research question you need answered
- Deploy the deep research protocol
- Verify the output
- Act on better information
In the next ZeroSkillAI guide, we’ll release exact settings and prompts to transform any LLM into a deep research machine. You’ll get copy-paste configurations for GPT-Researcher, optimal Perplexity search strategies, and verification checklists.
The research revolution isn’t coming—it’s here.
The question is: Will you be among those who find truth, or those who settle for the first answer they see?
Stop accepting surface-level answers. Start demanding evidence-based intelligence. Don’t settle for the first answer Google gives you. Start building your own deep research AI protocol today and transform how you process information forever.
Your research protocol is one weekend away. Truth is waiting.
Follow ZeroSkillAI.com for the complete deep research agent tutorial, copy-paste configurations, and verification frameworks. We’re democratizing intelligence gathering—no research degree required.
Want to apply research skills to business? Check our 100+ Best AI Side Hustles guide for ways to monetize information advantages.
Need foundational AI skills first? Our 10 Best Free AI Tools for Students covers essential platforms to master before building research agents.
Pingback: The Deep Research Machine: Exact AI Research Agent Prompts and Settings (2026 Zero Skill Guide) -